



2025.10.9
Research
Deepgram Fluxを使ったターンテイキング認識の実験

こんにちは
AIチームの戸田です
ここ数年で音声対話システムは急速に身近なものになりました。特に、ChatGPTのアドバンスドボイスモードのようなリアルタイムで会話できるプロダクトに触れていると技術の進化を強く実感します。
このような体験を支える重要な技術の一つが、システムと人との会話の順番を自然に交代する「ターンテイキング」です。以前、AIチームの大竹が検証した "MaAI" のように、この技術に特化したライブラリも開発されるなど、近年注目度が高まっています。
そのような中で先日、STT(Speech-to-Text: 音声認識)APIを提供するプラットフォームのDeepgramが音声認識とターンテイキングのための End of Turn (End of Turn: 相手の発話の終了)を同時に予測する Fluxというモデルを公開しました。本記事ではそのFluxを試してみたいと思います。
Deepgram Flux

背景
Deepgramは、元々Novaというモデルシリーズで高精度で低遅延なストリーミングSTTモデルを開発・提供していました。DeepgramのレポートではOpenAIのWhisperより認識精度が高く速度も速いと言われており、オンライン会議のリアルタイム文字起こしなどで活用されていました。
しかし、近年のLLMの進化から、音声認識そのものよりも、音声認識結果をどう活かすかがプロダクト上重要になってきました。特に音声対話システムのように「聞く」と「話す」が連続して行われる場面では、認識の速さが体験を大きく左右します。たとえば、ユーザーが話し終わって数秒遅れてAIが反応するだけで、「もたついた印象」を与えてしまいます。逆に、まだ話している途中で割り込むのも良くありません。
Fluxの登場
こうした課題に対して、Deepgramは Flux という新しいモデルシリーズを出しました。従来の音声認識モデルは "音声→テキスト" の変換を行うのみで、EoTの判断は、音声区間を検出する別のVAD(Voice Activity Detection)モデルを組み合わせる必要がありました。
ここでFlux は音声認識モデルの内部に発話が終わったかの判断を予測を行う仕組みを統合しました。これにより従来のVADが使っていた音響特徴だけでなく文脈的な情報をもとにEoT「発話の終わり」を推定できるようになります。例えば、Fluxは文末らしいイントネーションや文法構造も考慮しながら、発話が続くのかを判断すると言われています。
一点気をつけなければいけない点として、現在対応している言語は英語のみであることが挙げられます。日本語で試すことはできないので、この点は今後の多言語対応に期待です。
試してみる
事前準備
現在はPythonのみSDKが提供されています。pipでインストールします。
pip install deepgram-sdk加えて音声処理のためffmpegをインストール必要があります。Macの場合はbrewでインストールできます。
brew install ffmpegそしてDeepgramのコンソールで発行したAPI Keyを環境変数DEEPGRAM_API_KEYに設定しておきます。
検証コードについて
本来はマイク入力などstreamingでの認識を想定したライブラリですが、今回は実験のため、静的な音声ファイルをチャンクに区切って擬似的にstreamingで流します。コードはGistにアップロードしたので詳細はこちらをご参照ください。つまりそうなところが2箇所あったので、抜粋して以下で紹介します。
環境変数の設定位置from deepgram import AsyncDeepgramClientのようにdeepgramのSDKをimportする際に環境変数DEEPGRAM_API_KEYのチェックが走るので、dotenvなどを使う際はこの手前でloadするようにしてください。
eot_thresholdを設定する
公式のquickstartには記載がないのですが、EoTの予測を使用する際はDeepgramのAPIクライアント定義時に0.3〜0.9の範囲でeot_thresholdを設定する必要があります。今回は適当に中間の0.6を設定しました。
認識結果を確認してみる
Gistにあげたコードを実行すると--outputで指定した先に以下のカラムを持つcsvを出力します
- timestep: 時間(float)
- end_of_turn_confidence: EoTの確度(float)
- transcript: その時点で認識した単語(string)
- is_end_of_turn: EndOfTurnが反応したか(bool)
このcsvを同じくGistにあげたこちらのコードを使って可視化します。
音声は以下の「If we deploy this version today, we’ll probably need a rollback plan ready.」という私の声でテストします。
この文は途中に 従属節(if節) が挟まっており、カンマ部分での一時的な沈黙を「発話の終わり」と誤検出しやすい典型的なケースです。
本当にこれが難しい問題なのかを、Whisperと合わせてよく使われるVADライブラリのwebrtcvadを使って確認してみたいと思います。コードは同様にGistにアップロードしており、こちらを実行すると以下のような結果になりました。
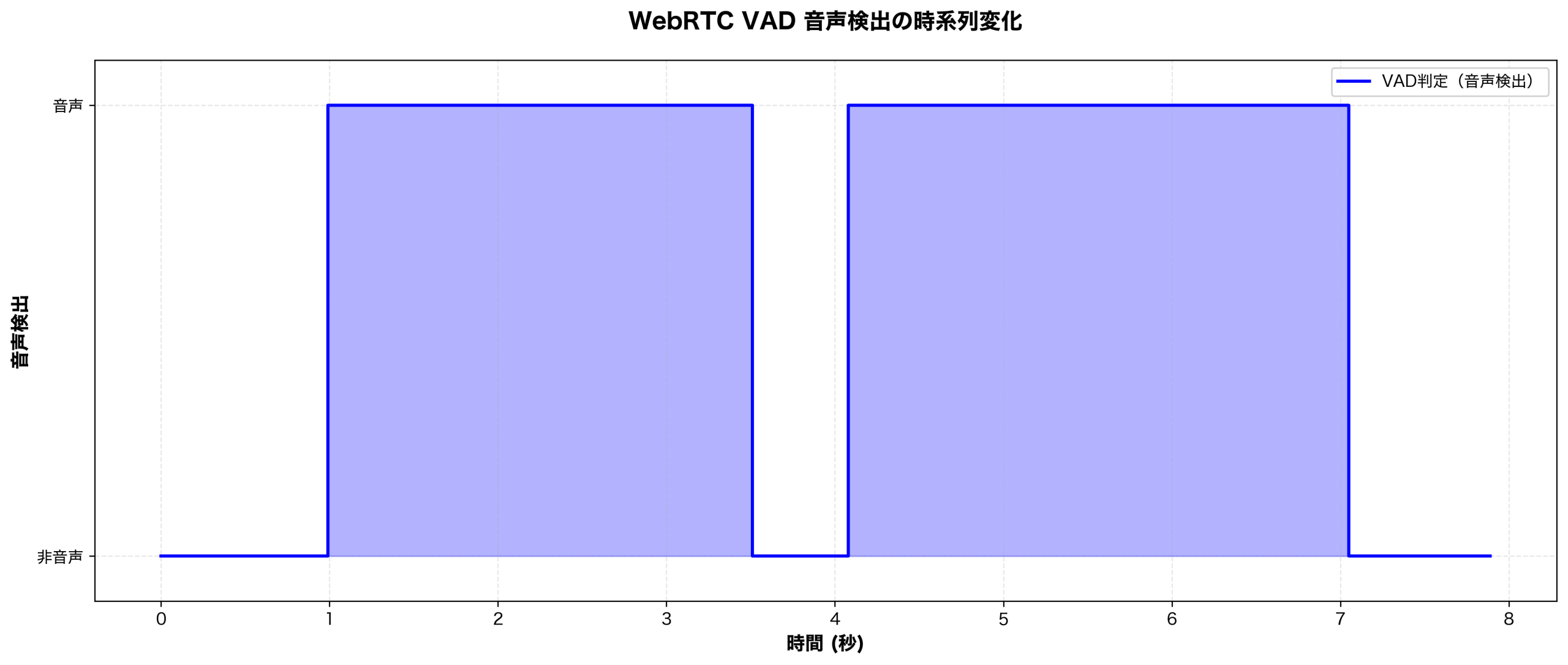
カンマのある4秒付近で非音声、つまりEoTになったと認識されてしまっています。フレーム長や区間融合のギャップなど調整すれば上手く認識できるかもしれませんが、人によって話し方は違いますし、なかなか難しい問題だということがわかります。
一方Deepgram Fluxを使った結果は以下になります。
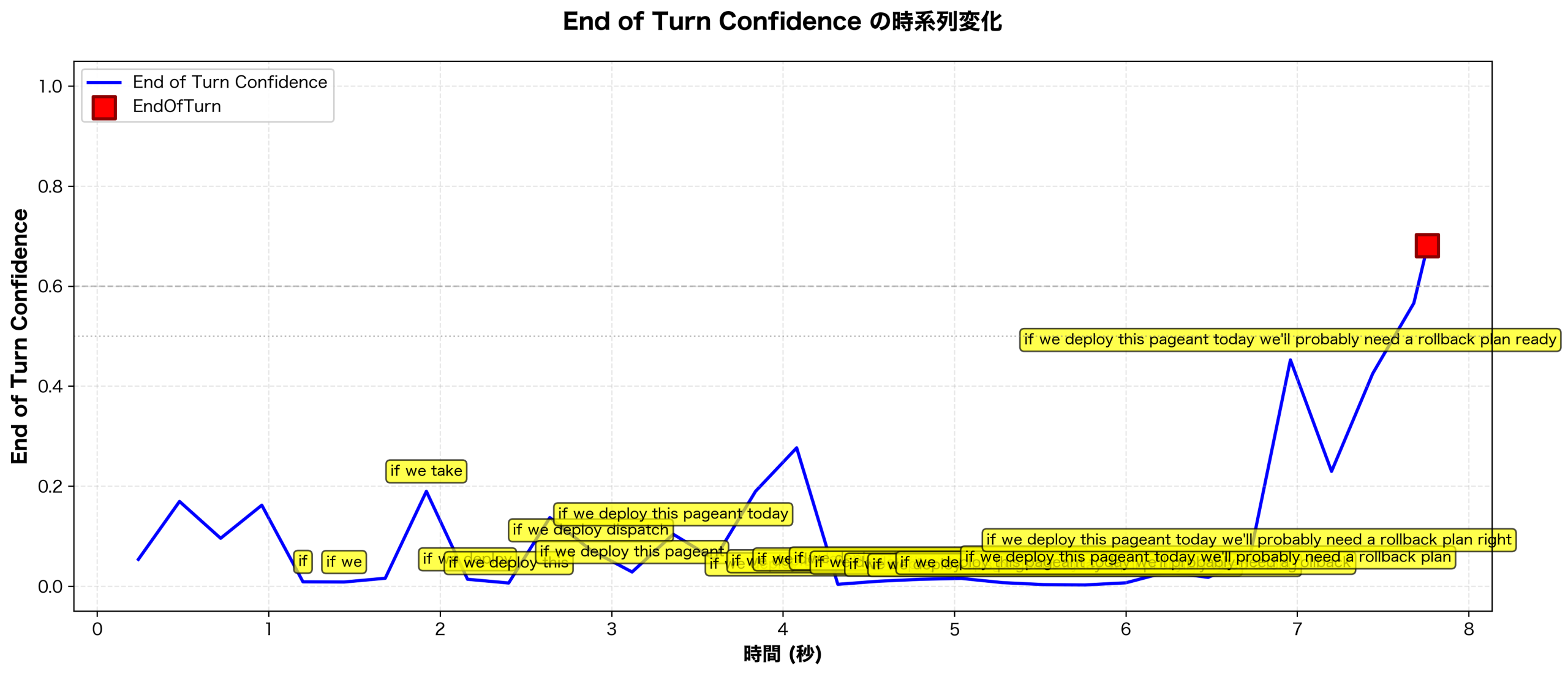
少し認識結果が重なって見えにくいですが、4秒くらいのカンマ部分で若干end_of_turn_confidenceが上がりつつも、EoT認識を抑えたのが確認できます。これは、Fluxが音響的な無音だけでなく、発話構造の文脈情報を参照していることを示しています。つまり“If we deploy this version today, …” のように条件節が続く構文では、文が完結していないことをモデルが理解し、一時的に end_of_turn_confidence が上がっても、最終的なEoT出力を抑え込んでいるのだと思われます。
おわりに
本記事では音声認識モデルの内部でEoTを同時に推定するDeepgram Fluxを試してみました。文法的構造を考慮してEoTを予測しており、音響的には無音だがまだ発話が続くようなケースをうまく扱える点がよかったです。
なお、今回は検証対象に含めませんでしたが、Fluxには EagerEndOfTurn というオプションが存在します。これは、通常のEoTよりも早い段階で「そろそろ終わりそうだ」と判断したタイミングを通知する機能で、返答の準備を始めるための信号として使われます。EagerEndOfTurnが発火しても実際のEoTが確定しなければ、TurnResumed という信号が返り、再び音声認識を継続する仕組みになっています。特に応答生成にLLMを利用する場合、早くレスポンス準備を始められることは体験上大きな利点となり、よりテンポの良い対話を可能にします。
EoTとEagerEndOfTurnの二段構えによって、「発話が終わった」だけでなく「終わりそうだ」も検出できる点で、Fluxは従来の音声認識モデルには無い良さがあると思います。現在は英語のみ対応ですが、日本語も対応されることを期待して、今後もウォッチを続けたいと思います。
最後までお読みいただき、ありがとうございました!