こんにちは!
AIチームの戸田です!
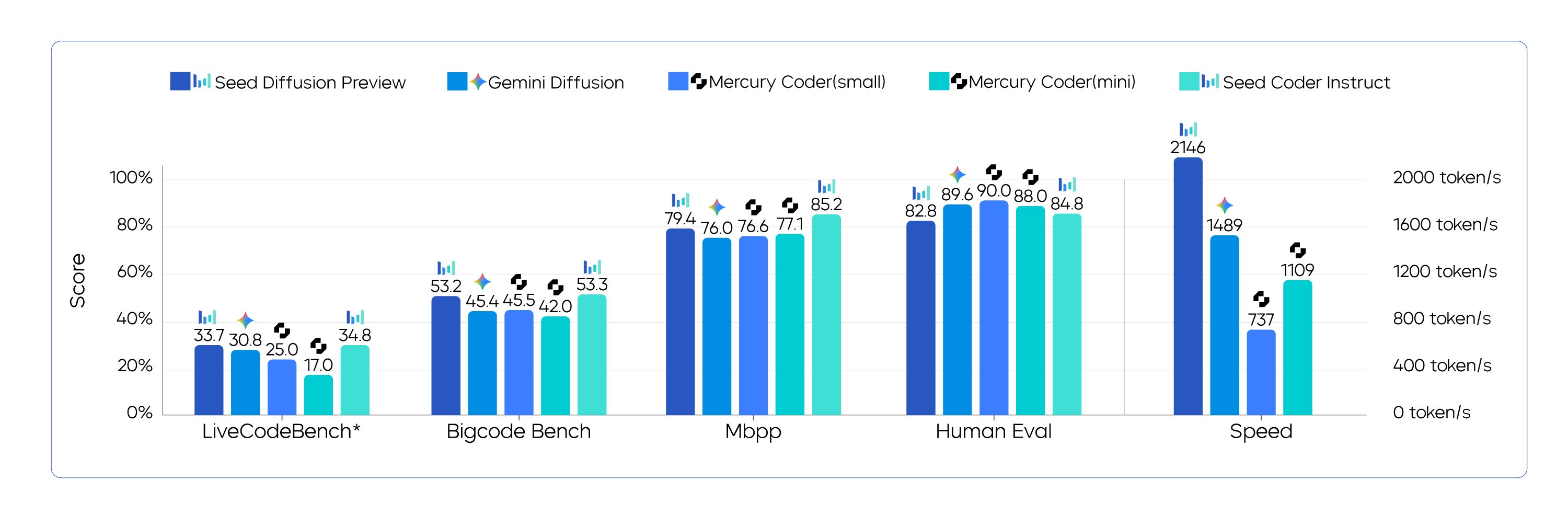
最近のLLM界隈では、推論速度の高速化が大きなトレンドになっています。先日、TikTokを運営しているByteDanceが公開したSeed Diffusionという拡散言語モデルもその流れを汲むものの一つだと思われます。サーバーが混雑しているようで、私は試すことはできなかったのですが、実験結果を見る限り、性能を保ちつつ、非常に高速な推論が可能になっているように見えました。
こうした高速化のトレンドを眺めていて、私も拡散言語モデルの速度を活かした何か面白いものを作ってみたくなりました。そこで今回作ったのが、拡散言語モデルを使ったリアルタイムなアプリケーション生成システムです。(※)
簡単に説明すると、ユーザーの要望に基づいて、その場でアプリケーションのUIやロジックをHTMLで生成し、すぐに実行可能な形で提供するというものです。
技術としては従来の自己回帰型モデルでも実現可能なものですし、既にv0やboltのようなプロダクトとしても一般的になっていますが、拡散言語モデルであればより高速な推論が可能なので、ユーザーの待ち時間を最小限に抑えることができ、また違った体験があるのではないか、と考えました。
前置きが長くなりましたが、本記事では、拡散言語モデルを使って、リアルタイムにアプリケーションを生成するシステムを作った際に実装上工夫した点と実際にどのように動くのかのデモを共有したいと思います。
拡散言語モデルの原理や挙動については以前も記事を書いておりますので、そちらを参照いただければと思います。(参考1, 参考2)
※: こちらはDeepMindのGemini 2.5 Flash Liteのデモに触発されたアイディアです
使用する拡散言語モデル
生成に利用するのはInceptionLabsのMercury Coderです。こちらはコード生成に特化した拡散言語モデルで、従来の自己回帰型モデルと比較して5〜10倍高速な推論が可能とされています。
現状APIで一般利用可能な拡散言語モデルはこれしかないのですが、コード生成に特化しているため、今回の用途には十分な性能を持っていると思い、採用しました。
簡単にリクエスト方法を紹介しておきます。
curl https://api.inceptionlabs.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer INCEPTION_API_KEY" \
-d '{
"model": "mercury",
"messages": [
{"role": "user", "content": "What is a diffusion model?"}
],
"max_tokens": 1000
}'拡散言語モデルは自己回帰型モデルと異なり、Suffixを指定することもできます。こういった細かいテクニックはドキュメントをご参照いただければと思います。
実装紹介
Next.js 15 + TypeScript + Tailwind CSSで作成しました。コードは全てGitHubで公開していますので、興味のある方はぜひご覧ください。以下より工夫した点を紹介させていただきます。
UI
PCのデスクトップ画面のような体験を意識しました
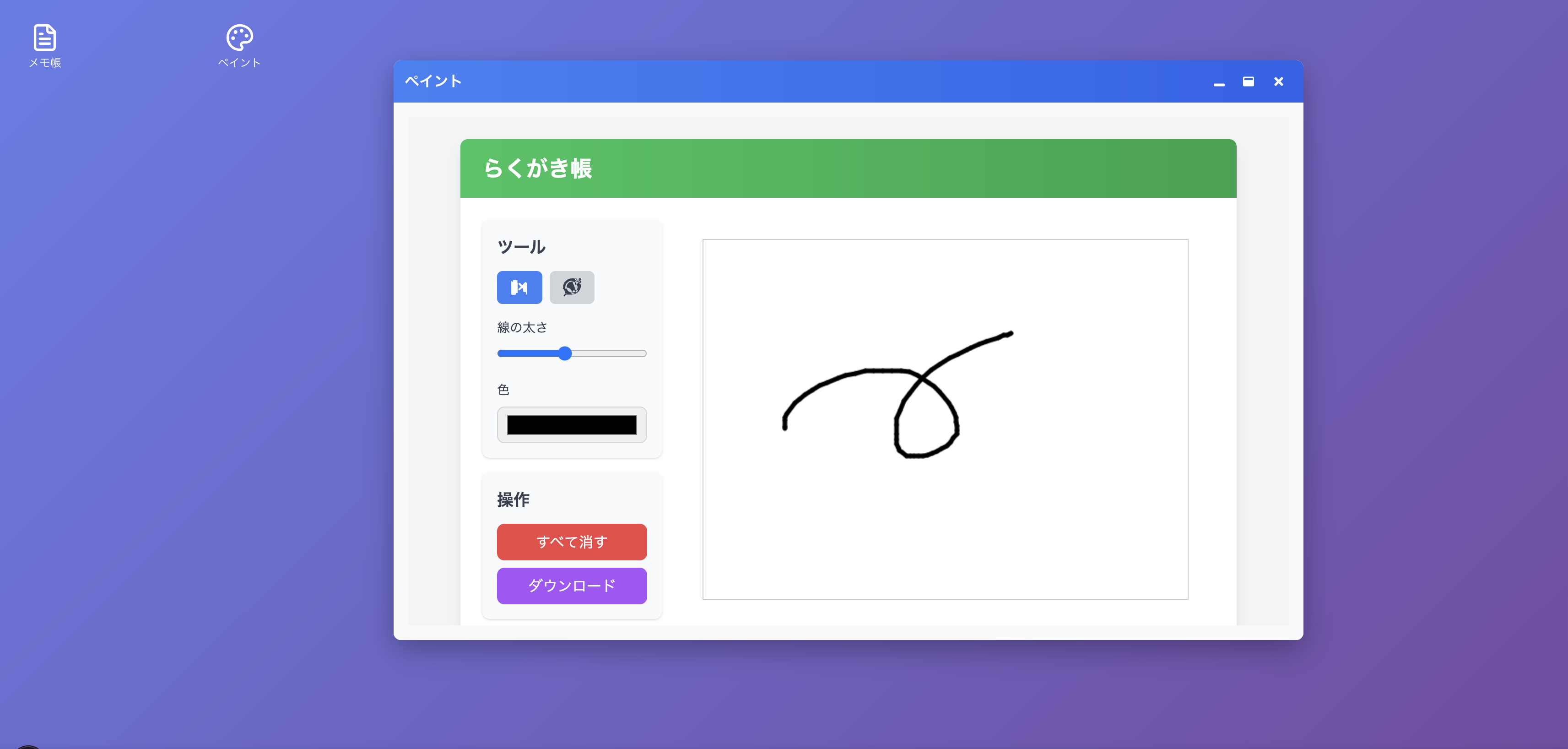
フォーマット固定するためのfew-shot prompt
LLMに完全なHTMLを出させるため、あらかじめ事前に作った「メモ帳アプリ」の完全なHTMLを例(few-shot)として提示し、出力形式を強く誘導しています。
コードでいうとこちらの部分が該当しますので、興味のある方はご参照いただければと思います。
生成UIの実行(iframe srcDoc + sandbox)
返ってきたHTMLはHTMLコードを文字列として直接指定するiframe srcDocで描画します。これにより、ファイルを作成・ホスティングする必要なく、動的に生成したHTMLをその場で<iframe>内に表示できます。これにより、ビルドは不要で、“その場で動く”体験を実現しようとしました。
デモアプリなので、セキュリティ的な部分はあまり気にしませんでしたが、sandbox="allow-scripts allow-same-origin"のみを付与し、権限を最小限に抑えるようにしました。
アイコン自動選択
生成されるアプリのアイコンは、説明文に基づいてLucide Reactの中から1つだけ適したアイコンを返すようにLLMを誘導しています。例えばお絵描きができるペイントアプリだったらパレットのアイコン、といった感じです。
デモ
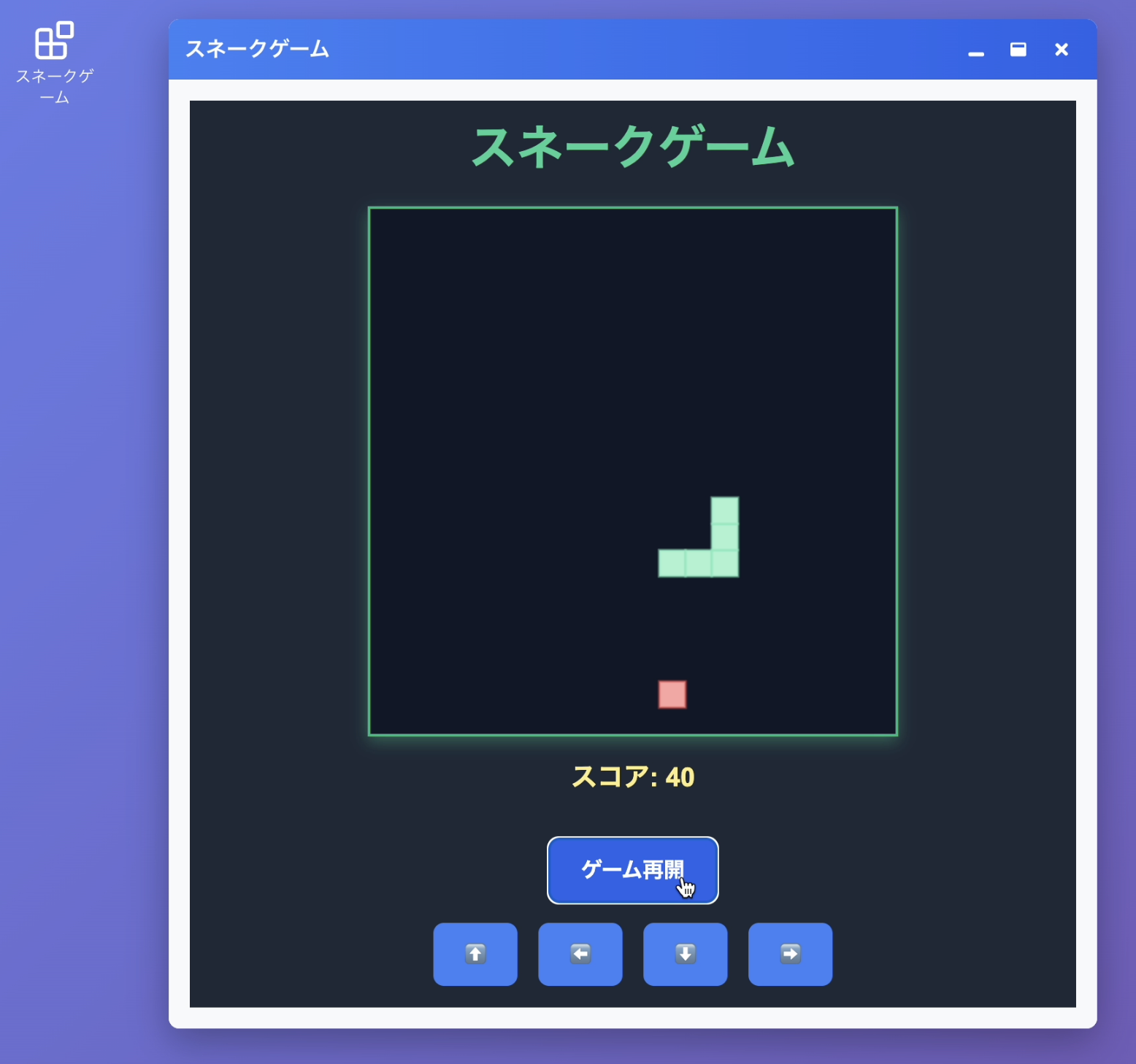
作成したアプリを使って「メモ帳」と「ペイント」を作ってもらいました。UIが生成されるのはアプリを作ったタイミングではなく、アプリを開くタイミングです。
きちんと動作するアプリができていますね。ちなみに「スネークゲーム」のようなちょっと複雑なアプリも問題なく作成できました。
せっかくなので自己回帰型モデルで最速と思われるGemini 2.5 Flash Liteとアプリの生成速度を比較してみました。私の動画編集スキルがしょぼかったので、キャプションが入れられなかったのですが、上がGeminiで下がMercury Coderです。
Geminiが大体6秒かかるのに対してMercury Coderは約4秒ほどで生成できています。ドハティのしきい値(0.4秒)からすると、どちらも時間がかかり過ぎなので、今後に期待かもしれません。個人的な感覚ですが、わずかな差ではありますが、何回も使っているとGeminiよりも使用感は良かったように感じました。
おわりに
今回は拡散言語モデルを使ったリアルタイムなアプリケーション生成システムを作ってみました。
従来の自己回帰型モデルに比べて待ち時間の少ない生成はなかなか体験がよかったですが、実応用となるとまだまだ高速化が必要かもしれません。
Mercury Coderのような拡散言語モデルに加えて、最近ではgroqやcerebrasのようなLLM推論に特化したハードウェアによる推論APIも出現してきているので、今後はリアルタイム性のあるLLMアプリケーションが増えてくるのではないかと期待しています。CodingAgentのような開発者の生産性向上にも大きく貢献するのではないでしょうか。
最後までお読みいただきありがとうございました!




